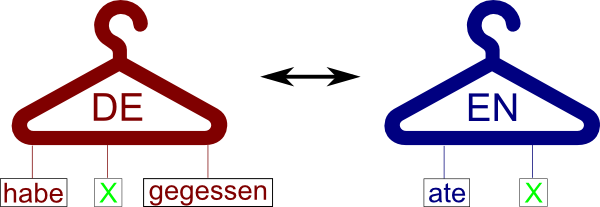
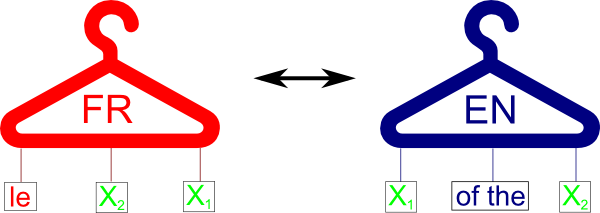
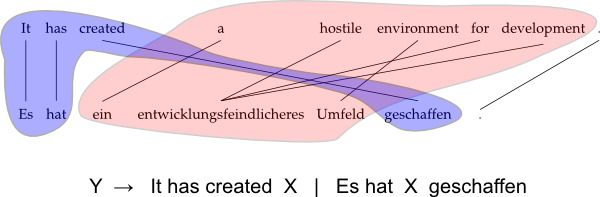
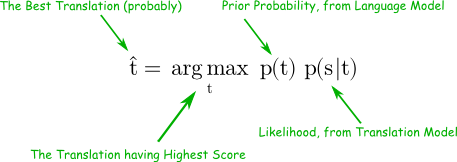
This course gives an introduction to machine translation. Since the audience for this class is both computational linguists and translators, we will cover both the theory of how it works as well as how to use it in everyday work.
mkdir ~/corpora
cd ~/corpora
wget -c http://www.statmt.org/wmt15/training-parallel-nc-v10.tgz wget -c http://www.statmt.org/wmt15/dev-v2.tgz
tar zxvf training-parallel-nc-v10.tgz tar zxvf dev-v2.tgz
~/moses/scripts/tokenizer/tokenizer.perl -l de \ < news-commentary-v10.de-en.de \ > news-commentary-v10.de-en.tok.de ~/moses/scripts/tokenizer/tokenizer.perl -l en \ < news-commentary-v10.de-en.en \ > news-commentary-v10.de-en.tok.en
~/moses/scripts/recaser/train-truecaser.perl \ --model truecase-model.de \ --corpus news-commentary-v10.de-en.tok.de ~/moses/scripts/recaser/train-truecaser.perl \ --model truecase-model.en \ --corpus news-commentary-v10.de-en.tok.en
~/moses/scripts/recaser/truecase.perl \ --model truecase-model.de \ < news-commentary-v10.de-en.tok.de \ > news-commentary-v10.de-en.tok.truecase.de ~/moses/scripts/recaser/truecase.perl \ --model truecase-model.en \ < news-commentary-v10.de-en.tok.en \ > news-commentary-v10.de-en.tok.truecase.en
cd ~/moses wget https://github.com/moses-smt/mgiza/archive/master.zip mv master.zip mgiza.zip
unzip mgiza.zip mv mgiza-master mgiza cd mgiza/mgizapp
cmake .
make -j 4
cp scripts/*.{sh,py,pl} bin/
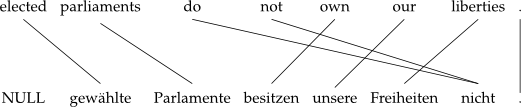
elected parliaments do not own our liberties .
NULL ({ }) gewählte ({ 1 }) Parlamente ({ 2 }) besitzen ({ 5 }) unsere ({ 6 }) Freiheiten ({ 7 }) nicht ({ 3 4 }) . ({ 8 })
cd ~/corpora wget http://jon.dehdari.org/teaching/uds/moses/moses_ems_nc10.conf
nano moses_ems_nc10.conf
~/moses/scripts/ems/experiment.perl -config moses_ems_nc10.conf
nice ~/moses/scripts/ems/experiment.perl -config moses_ems_nc10.conf -exec